MoritzLaurer/deberta-v3-large-zeroshot-v2.0
Model description: deberta-v3-large-zeroshot-v2.0
zeroshot-v2.0 series of models
Models in this series are designed for efficient zeroshot classification with the Hugging Face pipeline. These models can do classification without training data and run on both GPUs and CPUs. An overview of the latest zeroshot classifiers is available in my Zeroshot Classifier Collection.
The main update of this zeroshot-v2.0 series of models is that several models are trained on fully commercially-friendly data for users with strict license requirements.
These models can do one universal classification task: determine whether a hypothesis is "true" or "not true" given a text
(entailment vs. not_entailment).
This task format is based on the Natural Language Inference task (NLI).
The task is so universal that any classification task can be reformulated into this task by the Hugging Face pipeline.
Training data
Models with a "-c" in the name are trained on two types of fully commercially-friendly data:
- Synthetic data generated with Mixtral-8x7B-Instruct-v0.1.
I first created a list of 500+ diverse text classification tasks for 25 professions in conversations with Mistral-large. The data was manually curated.
I then used this as seed data to generate several hundred thousand texts for these tasks with Mixtral-8x7B-Instruct-v0.1.
The final dataset used is available in the synthetic_zeroshot_mixtral_v0.1 dataset
in the subset
mixtral_written_text_for_tasks_v4. Data curation was done in multiple iterations and will be improved in future iterations. - Two commercially-friendly NLI datasets: (MNLI, FEVER-NLI). These datasets were added to increase generalization.
- Models without a "
-c" in the name also included a broader mix of training data with a broader mix of licenses: ANLI, WANLI, LingNLI, and all datasets in this list whereused_in_v1.1==True.
How to use the models
#!pip install transformers[sentencepiece]
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
multi_label=False forces the model to decide on only one class. multi_label=True enables the model to choose multiple classes.
Metrics
The models were evaluated on 28 different text classification tasks with the f1_macro metric.
The main reference point is facebook/bart-large-mnli which is, at the time of writing (03.04.24), the most used commercially-friendly 0-shot classifier.
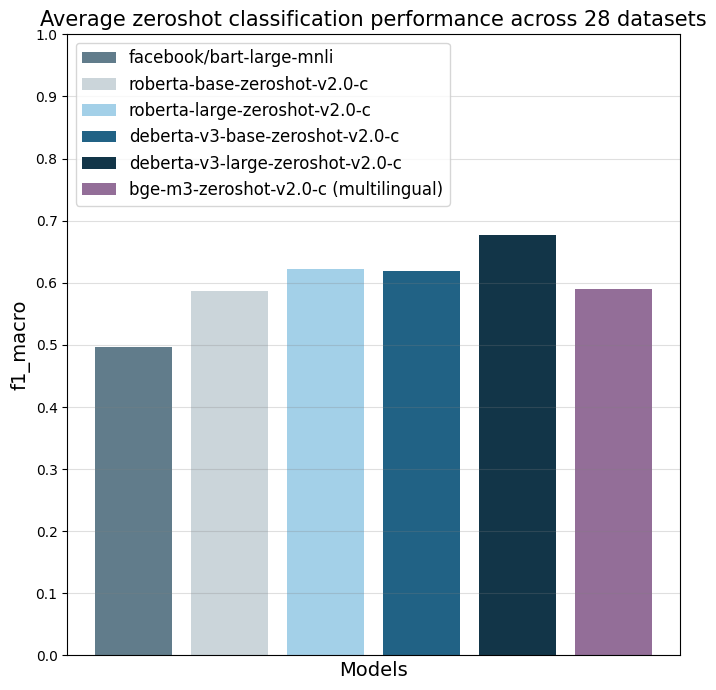
| facebook/bart-large-mnli | roberta-base-zeroshot-v2.0-c | roberta-large-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0 (fewshot) | deberta-v3-large-zeroshot-v2.0-c | deberta-v3-large-zeroshot-v2.0 (fewshot) | bge-m3-zeroshot-v2.0-c | bge-m3-zeroshot-v2.0 (fewshot) | |
|---|---|---|---|---|---|---|---|---|---|
| all datasets mean | 0.497 | 0.587 | 0.622 | 0.619 | 0.643 (0.834) | 0.676 | 0.673 (0.846) | 0.59 | (0.803) |
| amazonpolarity (2) | 0.937 | 0.924 | 0.951 | 0.937 | 0.943 (0.961) | 0.952 | 0.956 (0.968) | 0.942 | (0.951) |
| imdb (2) | 0.892 | 0.871 | 0.904 | 0.893 | 0.899 (0.936) | 0.923 | 0.918 (0.958) | 0.873 | (0.917) |
| appreviews (2) | 0.934 | 0.913 | 0.937 | 0.938 | 0.945 (0.948) | 0.943 | 0.949 (0.962) | 0.932 | (0.954) |
| yelpreviews (2) | 0.948 | 0.953 | 0.977 | 0.979 | 0.975 (0.989) | 0.988 | 0.985 (0.994) | 0.973 | (0.978) |
| rottentomatoes (2) | 0.83 | 0.802 | 0.841 | 0.84 | 0.86 (0.902) | 0.869 | 0.868 (0.908) | 0.813 | (0.866) |
| emotiondair (6) | 0.455 | 0.482 | 0.486 | 0.459 | 0.495 (0.748) | 0.499 | 0.484 (0.688) | 0.453 | (0.697) |
| emocontext (4) | 0.497 | 0.555 | 0.63 | 0.59 | 0.592 (0.799) | 0.699 | 0.676 (0.81) | 0.61 | (0.798) |
| empathetic (32) | 0.371 | 0.374 | 0.404 | 0.378 | 0.405 (0.53) | 0.447 | 0.478 (0.555) | 0.387 | (0.455) |
| financialphrasebank (3) | 0.465 | 0.562 | 0.455 | 0.714 | 0.669 (0.906) | 0.691 | 0.582 (0.913) | 0.504 | (0.895) |
| banking77 (72) | 0.312 | 0.124 | 0.29 | 0.421 | 0.446 (0.751) | 0.513 | 0.567 (0.766) | 0.387 | (0.715) |
| massive (59) | 0.43 | 0.428 | 0.543 | 0.512 | 0.52 (0.755) | 0.526 | 0.518 (0.789) | 0.414 | (0.692) |
| wikitoxic_toxicaggreg (2) | 0.547 | 0.751 | 0.766 | 0.751 | 0.769 (0.904) | 0.741 | 0.787 (0.911) | 0.736 | (0.9) |
| wikitoxic_obscene (2) | 0.713 | 0.817 | 0.854 | 0.853 | 0.869 (0.922) | 0.883 | 0.893 (0.933) | 0.783 | (0.914) |
| wikitoxic_threat (2) | 0.295 | 0.71 | 0.817 | 0.813 | 0.87 (0.946) | 0.827 | 0.879 (0.952) | 0.68 | (0.947) |
| wikitoxic_insult (2) | 0.372 | 0.724 | 0.798 | 0.759 | 0.811 (0.912) | 0.77 | 0.779 (0.924) | 0.783 | (0.915) |
| wikitoxic_identityhate (2) | 0.473 | 0.774 | 0.798 | 0.774 | 0.765 (0.938) | 0.797 | 0.806 (0.948) | 0.761 | (0.931) |
| hateoffensive (3) | 0.161 | 0.352 | 0.29 | 0.315 | 0.371 (0.862) | 0.47 | 0.461 (0.847) | 0.291 | (0.823) |
| hatexplain (3) | 0.239 | 0.396 | 0.314 | 0.376 | 0.369 (0.765) | 0.378 | 0.389 (0.764) | 0.29 | (0.729) |
| biasframes_offensive (2) | 0.336 | 0.571 | 0.583 | 0.544 | 0.601 (0.867) | 0.644 | 0.656 (0.883) | 0.541 | (0.855) |
| biasframes_sex (2) | 0.263 | 0.617 | 0.835 | 0.741 | 0.809 (0.922) | 0.846 | 0.815 (0.946) | 0.748 | (0.905) |
| biasframes_intent (2) | 0.616 | 0.531 | 0.635 | 0.554 | 0.61 (0.881) | 0.696 | 0.687 (0.891) | 0.467 | (0.868) |
| agnews (4) | 0.703 | 0.758 | 0.745 | 0.68 | 0.742 (0.898) | 0.819 | 0.771 (0.898) | 0.687 | (0.892) |
| yahootopics (10) | 0.299 | 0.543 | 0.62 | 0.578 | 0.564 (0.722) | 0.621 | 0.613 (0.738) | 0.587 | (0.711) |
| trueteacher (2) | 0.491 | 0.469 | 0.402 | 0.431 | 0.479 (0.82) | 0.459 | 0.538 (0.846) | 0.471 | (0.518) |
| spam (2) | 0.505 | 0.528 | 0.504 | 0.507 | 0.464 (0.973) | 0.74 | 0.597 (0.983) | 0.441 | (0.978) |
| wellformedquery (2) | 0.407 | 0.333 | 0.333 | 0.335 | 0.491 (0.769) | 0.334 | 0.429 (0.815) | 0.361 | (0.718) |
| manifesto (56) | 0.084 | 0.102 | 0.182 | 0.17 | 0.187 (0.376) | 0.258 | 0.256 (0.408) | 0.147 | (0.331) |
| capsotu (21) | 0.34 | 0.479 | 0.523 | 0.502 | 0.477 (0.664) | 0.603 | 0.502 (0.686) | 0.472 | (0.644) |
These numbers indicate zeroshot performance, as no data from these datasets was added in the training mix.
Note that models without a "-c" in the title were evaluated twice: one run without any data from these 28 datasets to test pure zeroshot performance (the first number in the respective column) and
the final run including up to 500 training data points per class from each of the 28 datasets (the second number in brackets in the column, "fewshot"). No model was trained on test data.
Details on the different datasets are available here: https://github.com/MoritzLaurer/zeroshot-classifier/blob/main/v1_human_data/datasets_overview.csv
When to use which model
- deberta-v3-zeroshot vs. roberta-zeroshot: deberta-v3 performs clearly better than roberta, but it is a bit slower. roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention. These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model. If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and HF Inference Endpoints).
- commercial use-cases: models with "
-c" in the title are guaranteed to be trained on only commercially-friendly data. Models without a "-c" were trained on more data and perform better, but include data with non-commercial licenses. Legal opinions diverge if this training data affects the license of the trained model. For users with strict legal requirements, the models with "-c" in the title are recommended. - Multilingual/non-English use-cases: use bge-m3-zeroshot-v2.0 or bge-m3-zeroshot-v2.0-c. Note that multilingual models perform worse than English-only models. You can therefore also first machine translate your texts to English with libraries like EasyNMT and then apply any English-only model to the translated data. Machine translation also facilitates validation in case your team does not speak all languages in the data.
- context window: The
bge-m3models can process up to 8192 tokens. The other models can process up to 512. Note that longer text inputs both make the mode slower and decrease performance, so if you're only working with texts of up to 400~ words / 1 page, use e.g. a deberta model for better performance. - The latest updates on new models are always available in the Zeroshot Classifier Collection.
Reproduction
Reproduction code is available in the v2_synthetic_data directory here: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
Limitations and bias
The model can only do text classification tasks.
Biases can come from the underlying foundation model, the human NLI training data and the synthetic data generated by Mixtral.
License
The foundation model was published under the MIT license. The licenses of the training data vary depending on the model, see above.
Citation
This model is an extension of the research described in this paper.
If you use this model academically, please cite:
@misc{laurer_building_2023,
title = {Building {Efficient} {Universal} {Classifiers} with {Natural} {Language} {Inference}},
url = {http://arxiv.org/abs/2312.17543},
doi = {10.48550/arXiv.2312.17543},
abstract = {Generative Large Language Models (LLMs) have become the mainstream choice for fewshot and zeroshot learning thanks to the universality of text generation. Many users, however, do not need the broad capabilities of generative LLMs when they only want to automate a classification task. Smaller BERT-like models can also learn universal tasks, which allow them to do any text classification task without requiring fine-tuning (zeroshot classification) or to learn new tasks with only a few examples (fewshot), while being significantly more efficient than generative LLMs. This paper (1) explains how Natural Language Inference (NLI) can be used as a universal classification task that follows similar principles as instruction fine-tuning of generative LLMs, (2) provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier, and (3) shares the resulting universal classifier that is trained on 33 datasets with 389 diverse classes. Parts of the code we share has been used to train our older zeroshot classifiers that have been downloaded more than 55 million times via the Hugging Face Hub as of December 2023. Our new classifier improves zeroshot performance by 9.4\%.},
urldate = {2024-01-05},
publisher = {arXiv},
author = {Laurer, Moritz and van Atteveldt, Wouter and Casas, Andreu and Welbers, Kasper},
month = dec,
year = {2023},
note = {arXiv:2312.17543 [cs]},
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language},
}
Ideas for cooperation or questions?
If you have questions or ideas for cooperation, contact me at moritz{at}huggingface{dot}co or LinkedIn
Flexible usage and "prompting"
You can formulate your own hypotheses by changing the hypothesis_template of the zeroshot pipeline.
Similar to "prompt engineering" for LLMs, you can test different formulations of your hypothesis_template and verbalized classes to improve performance.
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
# formulation 1
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
# formulation 2 depending on your use-case
hypothesis_template = "The topic of this text is {}"
classes_verbalized = ["political activities", "economic policy", "entertainment or music", "environmental protection"]
# test different formulations
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)